
Last summer I spoke at the US-UK Forum on Measuring Biodiversity at the National Academy of Sciences, jointly organised with the Royal Society. Two companion papers from that forum have just been published in PNAS to turn the Washington meeting into an agenda for transforming how the world monitors global biodiversity.



1 The nine recommendations for biodiversity
The key numbers in global biodiversity are pretty stark: roughly 1 million species threatened with extinction, a 70% decline in monitored wildlife populations since 1970, and insect populations declining at around 10% per decade.
Against this backdrop, the paper makes nine recommendations towards accelerating action:
-
Capitalise on novel technology to integrate data sources. This is partly where my work comes in! Geospatial foundation models like TESSERA, eDNA, acoustic monitoring and citizen science are generating data at scale. The challenge is combining these heterogeneous sources, which is where models like TESSERA fit by making downstream task combinations way more efficient. What's missing is effective labeling infrastructure to combine the observational knowledge from space with human expert knowledge on the ground (more on that later).
-
Agree standard methods for data collection. Inconsistency in methods hinders all major uses of biodiversity data, but it's not practitioners that are at fault: there's just a lot of different levels of biodiversity that need to be monitored. Consider how different even a medium sized back garden is from one end to the other, and then scale this out to a tropical rainforest. The paper calls for a tiered and modular monitoring workflow, which is described in detail in the companion BMSF paper.
-
Ensure new technologies are calibrated with existing data. As we race to upgrade technology, monitoring results from traditional field surveys (that might date back decades) need to be migrated to newer AI-driven workflows. But we must keep the primary observations distinct from the statistical derivations or else we poison our sources and confound long-term trends.
-
Fill data gaps using emerging technologies, especially in the tropics. Biodiversity data is geographically biased toward charismatic species in wealthy countries. Invertebrates, soil biota and tropical ecosystems are massively underrepresented; just check out Shane Weisz and his living RED list dashboard to see how poorly some taxa are represented in the overall picture.
-
Create living databases of trusted information to reduce AI poisoning. Our CE evidence TAP pipeline of the scientific literature shows how we need institutionally federated networks of living evidence with humans-in-the-loop who can continuously gather, screen and index literature. The alternatives of depending on blackbox and unaccountable LLMs is rapidly descending on us, and so we are building out dynamic meta-analysis and active vetting of literature databases to spot AI poisoning to not only reject fabricated papers but also to invalidate downstream damage in the citation networks.
-
Ensure data generation is valued. Last summer, David Coomes and I spoke at an IUCN meeting about how vital field-based data collection is for ground truth, especially as self-supervised AI advances. Incentives for data sharing need reform in the majority world where data is currently scarce, for example via governance for wholesale sharing, academic credit through coauthorship, recognition of data production as a research output, and sufficient resourcing for archival. My principles for collective knowledge capture much of this from a technical perspective, but of course regulatory and financial reform is also necessary to push incentives in the right direction.
-
Ensure respectful incorporation of Indigenous Knowledge. When I spoke at the CE conference recently, I carelessly used the term 'indigenous knowledge' to refer generically to grey literature, and E. J. Milner-Gulland quite rightly told me off afterwards! Indigenous knowledge systems are distinct in that they hold generations of environmental insight accumulated through direct interaction with ecosystems. I need to learn more about this all as it also came up at the Indian AI summit as well in the conversations about sovereignty. The paper stresses Free, Prior and Informed Consent and the CARE principles for Indigenous data governance. After our paper was published, WarīNkwī Flores also pointed out their work on sovereign data supply chains which is very complementary.
-
Ensure measurements enable quantification of effectiveness of actions. Monitoring outcomes without a focus on evaluating the impact of interventions is like redecorating while the house burns. High spatial and temporal resolution data (for instance, dynamic ground truth combined with geospatial models) could estimate credible counterfactuals (what would have happened without the intervention). This in turn enables evidence-based policy at much larger scale than we currently do. Most ecological mitigation recommendations in the UK are not evidence based, which means there's a lot of paperwork without much point!
-
Increase the resilience of global datasets to technical and societal change. This is a problem across society with the pace of AI, but it's particularly urgent for nature where business as usual results in mass extinctions if we take action in the wrong place. There are short term measures such as federation that will help, but I'm fascinated by the potential of our work on building an ecology for the internet that draws on ecological theory to make digital infrastructure more resilient. This is a pretty far-out prospect right now, but coding models have advanced massively in just one year since I wrote that paper, and there's a growing connection between biodiversity science and computer science. There will be a workshop on "Rewilding the Web" in Edinburgh (28-29 May 2026) exploring exactly these ideas of applying ecological insights to digital infrastructure resilience, so I hope to see you there if you are into this!
2 The Biodiversity Monitoring Standards Framework
The BMSF paper then provides a more concrete implementation to follow the flow of data. This is probably of more relevance to computer scientists as it covers a lot of practical ground for which we already have many piecemeal solutions in the tech world. The paper describes an iterative cycle:
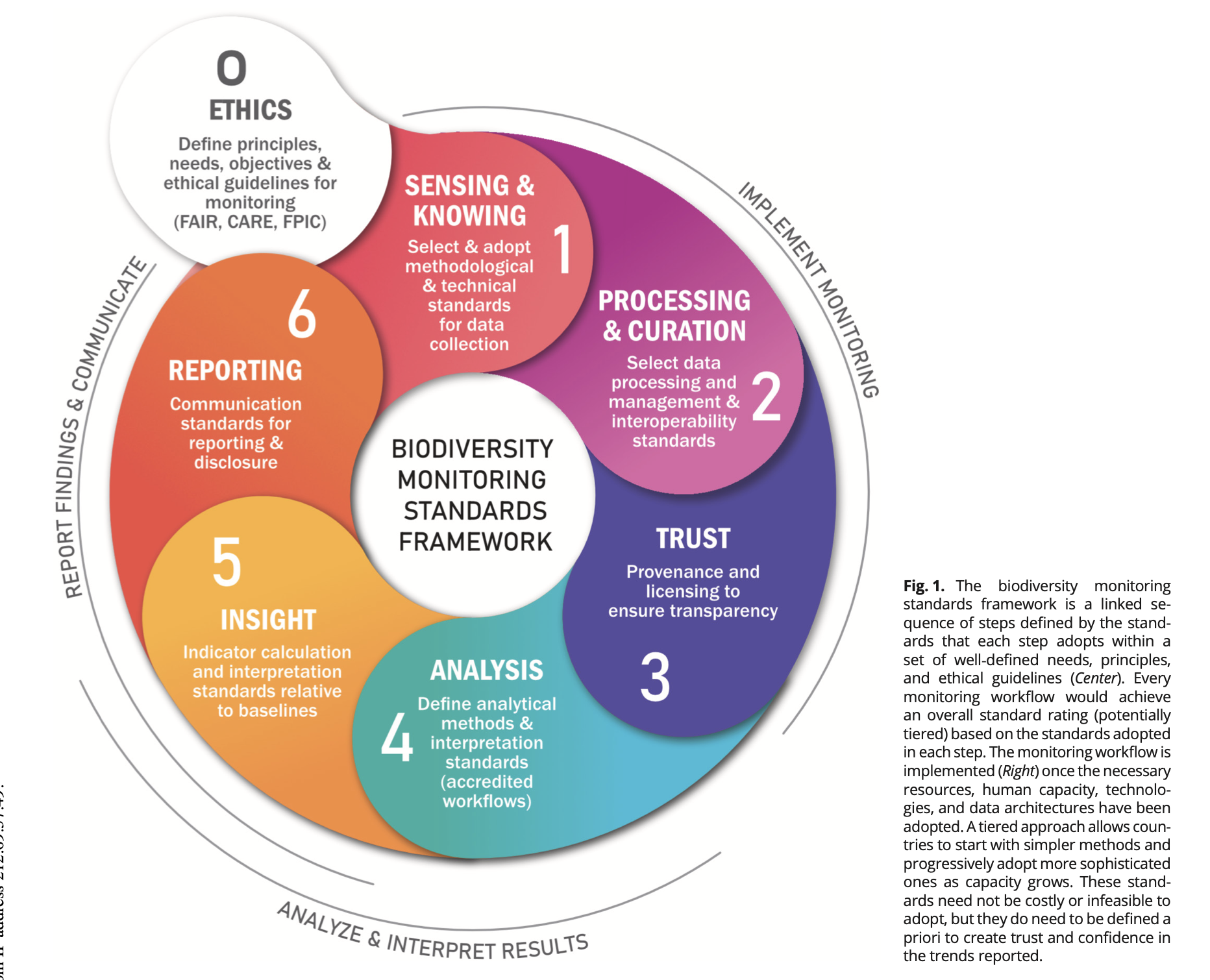
- Ethics: Foundational principles including FAIR, CARE, FPIC ethical guidelines covering respect for life, indigenous data sovereignty, data security, transparency of purpose, the precautionary principle, and equitable benefit-sharing.
- Sensing & Knowing: Standardised data collection from multiple evidence streams including fixed sensing, scientific methods, indigenous knowledge systems, and citizen science.
- Processing & Curation: Data validation, quality assurance, interoperability via standards like Darwin Core and multimodal integration where needed.
- Trust: Provenance and licensing towards trusting inputs (see earlier comments about AI poisoning), metadata, data lineage tracking, clear licensing and attribution, security protocols, and data sovereignty.
- Analysis: Standardised analytical approaches, uncertainty quantification based on groups of data and their sources, documented models and software that's reproducible (including training data for models, so bitwise not necessary)
- Insight: Indicator calculation and interpretation relative to baselines to generate counterfactuals, including long-term trend interpretation.
- Reporting: Consistent reporting formats, publishing for long-term accessibility, peer review mechanisms, and communication.
The framework is federated by design, in a manner quite compatible with Ostrom's guidelines as locally generated data flows into regional and national hubs which apply consistent analytical workflows, producing GBF-compatible indicators for international reporting. Countries or organisations can start with simple methods and progressively adopt more sophisticated approaches as their capacity grows.
For monitoring frameworks like REDD+ MRV, a centralized, top–down body like FAO makes sense given the direct link to the UNFCCC and IPCC and the coupling of climate observing systems to carbon stock and emissions models and assessments.
However, the multifaceted nature of biodiversity and the existing landscape of key organizations make a federated governance model, with national ownership at its heart, more appropriate and likely to succeed for the BMSF. -- Sec 2.4, From data to decisions: Toward a BMSF
The paper also provides a handy worked example for forest connectivity indicators under the maximum GBF Target 3, showing how each step produces a certified evidence chain for a full provenance chain from remote sensing to the final reported indicator value.
3 Connecting to collective knowledge systems
The BMSF maps on pretty well to the general principles for collective knowledge systems that I recently sketched out:
3.1 Permanence
"Permanence" maps to the BMSF's recommendation to use DOIs for datasets, version-controlled code pipelines, and long-term archiving. Rec 9 from the first paper makes the case that biodiversity data must survive political shocks, institutional closures and format obsolescence.
The BMSF's requirement for persistent identifiers at every step of the chain fits in nicely with the "DOIs for all" approach that Rogue Scholar and Zenodo have been pioneering for blogs and datasets (my own site uses both).
3.2 Permission
"Permission" connects to the BMSF's Ethics step and its emphasis on FAIR and CARE principles, indigenous data sovereignty, and tiered access. As I noted in my collective knowledge principles, biodiversity data is a prime example of where everything cannot be open: location data for endangered species could be exploited by poachers, and indigenous communities have sovereign rights over their own traditional knowledge.
The BMSF's federated model explicitly supports this as not all collected data needs to be shared openly, and the principle of "guardianship" enables tiered access levels. This is the kind of spatial permissioning that current Internet protocols handle poorly.
3.3 Placement
"Placement" maps to the BMSF's federated, nationally- and regionally-owned architecture. The tiered design allows countries to operate at their own level of capacity while still contributing to global assessments.
We're feeling this with TESSERA's multi-petabyte embeddings as well; they physically can't move casually between continents and networks, and so the processing must be distributed and federated rather than centralised. Aadi Seth has suggested a mirror in India as our first federated node!
3.4 Provenance
"Provenance" is at the centre of the BMSF as it is designed as an auditable chain of evidence where every indicator can be traced back through analytical methods, data processing, licensing and raw observations.
Our fifth recommendation calls out for hallucination-free AI systems for evidence synthesis, and the BMSF's Trust+Analysis phases provide the architecture to make provenance tracking systematic. The same provenance protocols we need for the broader Internet (tracking where knowledge came from and whether to trust it) apply even more to biodiversity data that informs actions affecting the abundances of millions of species.
There's also clear need for revamping peer review in this world, something that BON-in-a-Box is tackling. Our PROPL 2025 paper on programming the BON lays out some projects in this space, and the talk below is an excellent overview of the space for those computer scientists interested in learning more.
4 How this maps to my immediate research efforts
Several strands of the research in the EEG connect directly to what these papers are calling for!
4.1 TESSERA and labelling frameworks

Srinivasan Keshav and I are just starting work on a labelling framework that fits within the BMSF architecture, so that the ground-truth data used to finetune TESSERA for biodiversity applications can map to the standardised collection, curation and provenance requirements laid out in the framework. Since TESSERA itself is fully open and reproducible, this is a big step toward making AI-driven biodiversity assessments auditable end-to-end. There is also the intriguing possibility of using the ATProto to anchor the federation while re-using identity infrastructure across social networks, but we need to carefully consider issues of privacy. More on this as it develops!
4.2 Evidence synthesis and living databases
Our paper pipeline for analysing the academic literature at scale for Conservation Evidence is a working prototype of the "living databases" that the fifth recommendation calls for.
Dynamic meta-analysis, hallucination-free screening with humans in the loop, and continuous evidence ingestion are all on the table here, and the BMSF provides the architecture within which these tools can interoperate. We're just beginning a new project on this that also includes Education as well as conservation, which I'm very excited about!
4.3 Internet resilience meets biodiversity
The most fun and somewhat far out thing is our ecology of the internet work, which tries to draw a connection between ecological resilience principles and the digital infrastructure that biodiversity data depends on. This is a deliberately circular argument to see where the thoughts go: we need resilient digital infrastructure to monitor biodiversity, and ecological theory can teach us how to build that infrastructure.
The upcoming Rewilding the Web workshop in Edinburgh will bring together ecologists, philosophers and technologists to push this further. I'm also working with Cyrus Omar to figure out how to connect all these into a global live wiki, and Jon Ludlam is hacking on a prototype already!
These two perspective papers represent the published output of the conversations we had at the NAS last summer, and my own agenda is now a bit clearer. I want to connect models like TESSERA and our Cambridge TAP to federated, auditable monitoring systems that can transform the flood of biodiversity data into credible evidence that's urgently needed to halt and reverse nature loss. Stay tuned for some ideas I have about venues where we can do this together!
Read more about Nine changes needed to deliver a radical transformation in biodiversity measurement.